Pipeline Architecture
Alligator runs a sequential four-phase pipeline. Each phase is managed by a dedicated component inside AlligatorCoordinator.
Overview
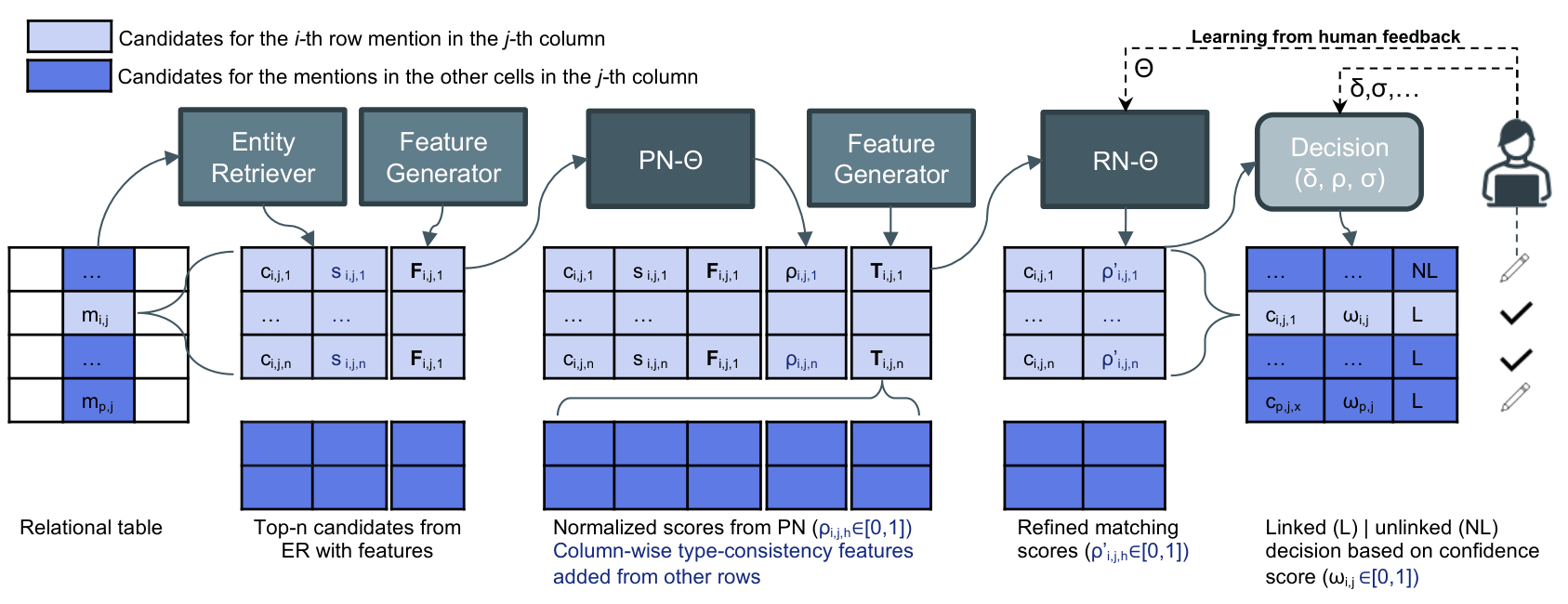
| Phase | Component | What happens |
|---|---|---|
| 1 – Data Onboarding | DataManager | Column classification, chunking, MongoDB ingestion |
| 2 – Worker Processing | WorkerManager + RowBatchProcessor | Async parallel: entity extraction → candidate fetch → feature computation |
| 3 – ML Pipeline | MLManager + MLWorker | Rank → global frequency computation → Rerank |
| 4 – Output | OutputManager | CSV generation and MongoDB annotation assembly |
| 0 – HTTP Ingestion | FastAPI backend | Optional REST entry point (see below) |
Phase 1: Data Onboarding
DataManager.onboard_data():
- Classifies each column as NE (Named Entity), LIT (Literal), or IGNORED using
column-classifier. - Accepts a
target_columnsoverride to skip auto-classification. - Chunks the DataFrame into MongoDB
input_datadocuments withstatus: TODO.
Each document carries a row slice, the column type map, and any user-supplied correct QIDs.
Phase 2: Worker Processing
WorkerManager spawns num_workers Python multiprocessing workers. Each worker runs an async event loop and processes batches of rows via RowBatchProcessor:
- Entity extraction — parses NE cell values into
Entityobjects, normalises NER type labels (LOC,ORG,PERS,OTHERS). - Candidate retrieval —
CandidateFetcher:- Checks the SHA-256 keyed MongoDB TTL cache (2-hour TTL, 500 MB cap).
- POSTs to the LAMAPI entity retrieval endpoint.
- Retries with fuzzy matching if no results are returned.
- Uses 5-attempt exponential backoff on network failures.
- Feature computation —
Feature.process_candidates()fills description similarity, n-gram overlap, and the full 27-feature vector per candidate. - LAMAPI enrichment (optional) —
ObjectFetcherandLiteralFetcherpopulate NE–NE relationship and NE–LIT value features. - Persistence — bulk-writes candidates to MongoDB and marks rows
status: DONE.
Phase 3: ML Pipeline
Two-stage ranking is used to break the global-feature chicken-and-egg problem: the CTA/CPA frequency features (cta_t1…t5, cpa_t1…t5) require all rows to be provisionally ranked first.
Stage 1: Rank
MLWorkerloads the Keras.h5ranking model.- Claims document batches atomically via
find_one_and_update. - Builds a
(N, 27)float feature matrix — CTA/CPA features set to zero. - Calls
model.predict()and normalises scores per-cell. - Applies
RAW_MIN_CONFIDENCEfloor.
Global Frequency Computation
Feature.compute_global_frequencies() aggregates over all ranked rows:
type_frequencies[col]— frequency distribution of candidate Wikidata types per column.predicate_frequencies[col]— frequency of predicates linking NE columns.predicate_pair_frequencies[col_pair]— predicate pair frequencies.
Stage 2: Rerank
- Same
MLWorkerarchitecture, but with the reranker model. - Injects computed
cta_t1…t5andcpa_t1…t5global frequency features. - Applies the final match decision rule:
match = (norm_score_top ≥ MATCH_THRESHOLD)
OR (norm_score_top − norm_score_second ≥ MATCH_MARGIN_DELTA)
- Writes
cea/cta/cpaannotations back toinput_data.
Phase 4: Output
OutputManager.save_output():
- Cursors through
input_data. - Synthesises output columns:
_id,_name,_score,_match,_types,_predicates. - Writes a CSV file if
save_output_to_csv=True.
Phase 0: HTTP Ingestion (Optional)
When using the FastAPI backend (backend/):
POST /dataset/{name}/table/json
- Receives a table payload and upserts dataset metadata.
- Auto-classifies columns via
ColumnClassifier. - Spawns a background task that triggers the full pipeline.
Results can be read back via:
GET /datasets/{dataset_id}/tables/{table_id}
Data Flow
CSV / DataFrame
│
▼
┌─────────────────────────────────────┐
│ Phase 1 — DataManager │
│ column classification → MongoDB │
│ input_data (status: TODO) │
└────────────────┬────────────────────┘
│ N parallel workers
▼
┌─────────────────────────────────────┐
│ Phase 2 — WorkerManager │
│ entity extract → fetch candidates │
│ → compute features → bulk write │
│ input_data (status: DONE) │
│ candidates collection │
└────────────────┬────────────────────┘
│
▼
┌─────────────────────────────────────┐
│ Phase 3 — MLManager │
│ Rank (local features only) │
│ → global freq computation │
│ → Rerank (with CTA/CPA features) │
│ → cea / cta / cpa annotations │
└────────────────┬────────────────────┘
│
▼
┌─────────────────────────────────────┐
│ Phase 4 — OutputManager │
│ assemble results → CSV / API │
└─────────────────────────────────────┘
MongoDB Collections
| Collection | Purpose |
|---|---|
input_data | Input rows + final annotations (CEA/CTA/CPA) |
candidates | Candidate entities per cell |
candidate_cache | SHA-256 keyed TTL cache for retrieval responses |
object_cache | Cache for object relationship API responses |
literal_cache | Cache for literal value API responses |
error_logs | Error records from worker processing |
datasets | Dataset-level metadata (FastAPI backend) |
tables | Table-level metadata (FastAPI backend) |